Daniel Iglesias

I am a Machine Learning & Analytics Analyst with a degree in Industrial Engineering. Currently specializing in data science.
Check out my latest projects and click on the link to see them in detail.
View the Project on GitHub Melo97/Daniel-Iglesias_Portifolio
Portfolio
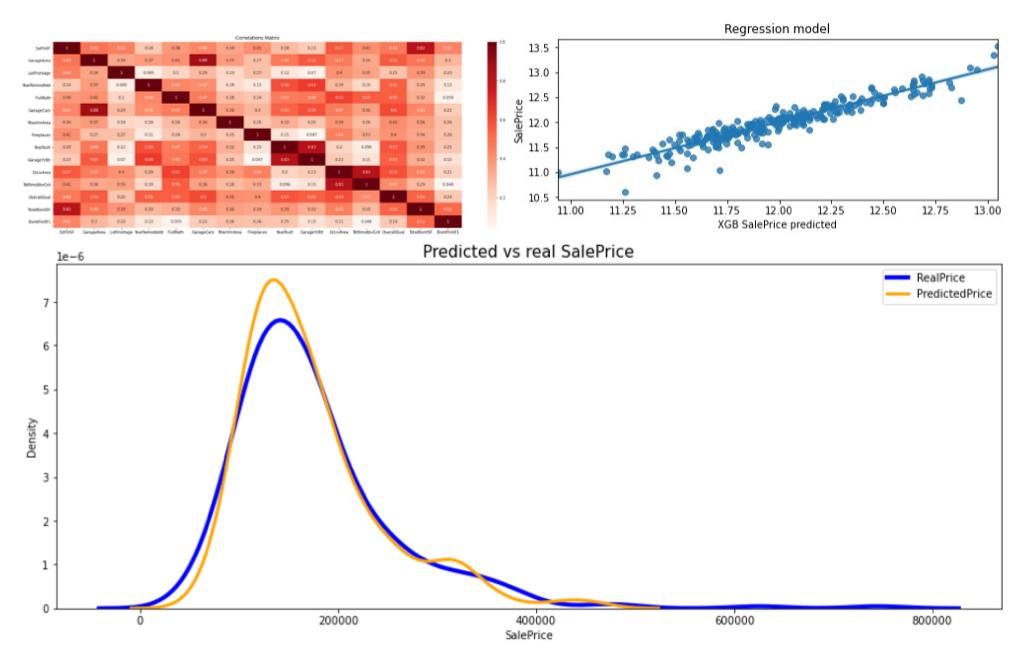
Predicting House Prices with Random Forest & XGBoost
Skills: Python, Random Forest, XGBoost
With detailed EDA and Feature Engineering, this model was trained to accuretly predict Houses Sale Price, using three Regression methods: Random Forests, Extreme Gradient Boosting, and a compound of both. The resulting model performed accurately on testing phase.
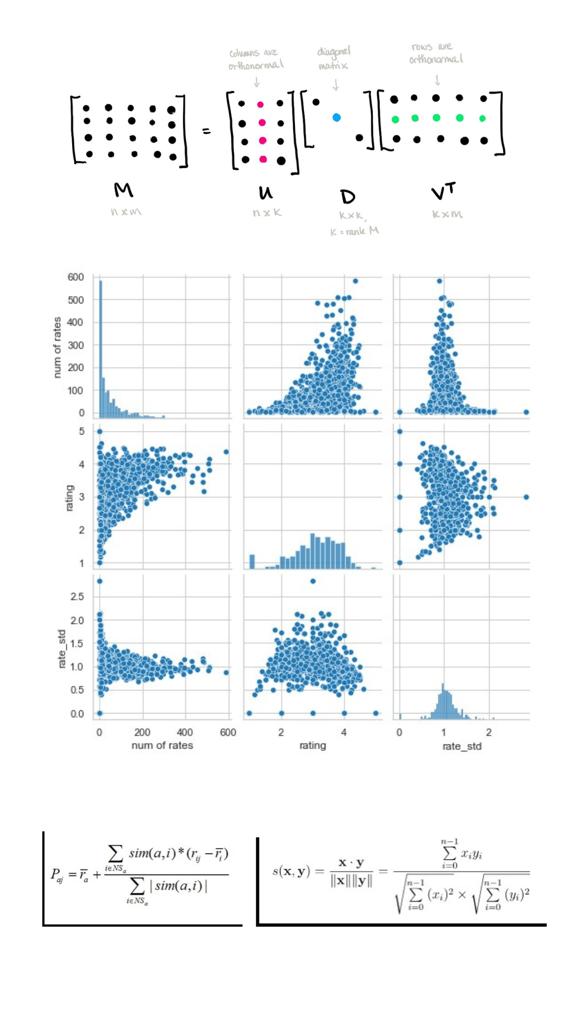
Movie Recommendation Systems for Streaming Platforms
Skills: Linear Algebra, Content-based & Collaborative Filtering Recommending Systems
Built over a large UCI movie ratings dataset, this project was grounded on different approaches of ML Recommending Systems - Content-based, Model-based, and Memory-based Systems - with the goal of evaluating which of them were better suited in terms of simplicity, computing capacity, and performance
Assessing Climate Change using CNN via vegetation identification
Skills: Neural Networks, Deep Learning, Image Recognition
Using Tensorflow Keras, created a Convolutional Neural Network able to predict, with high precision, the presence of a certain type of vegetation in satellite images, which are related to environmental damage activities. The model classified labels correctly 94% of the time for the class of interest and 93% for the other.

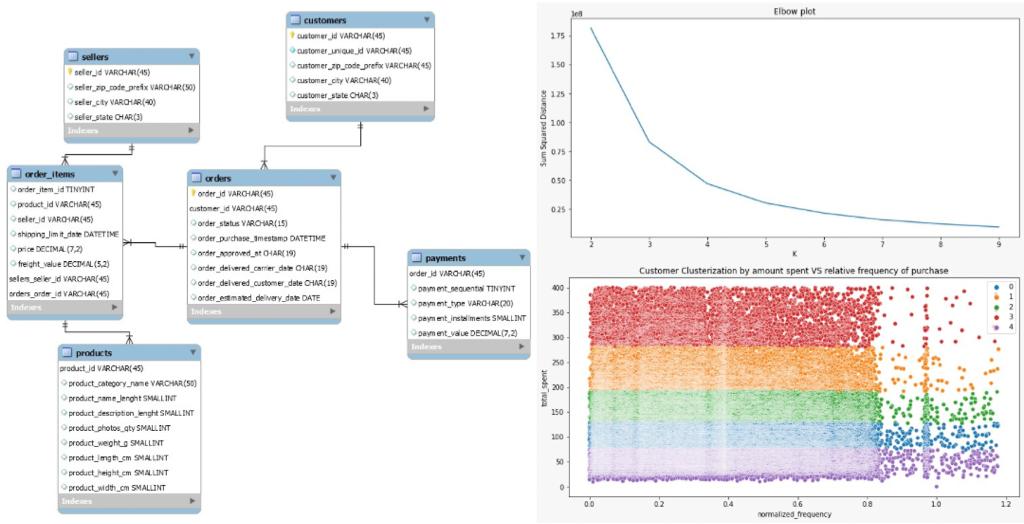
Customer Clustering using K means
Skills: SQL, mySQL, Python, KMeans
This project was develop to dynamically clusterize customers to an E-commerce database, based on Frequency and Amount of Money Spent, to better tailor marketing resource allocation. It was used KMeans to define the customers importance, and mySQL to create and maintin (UPDATE) the database.
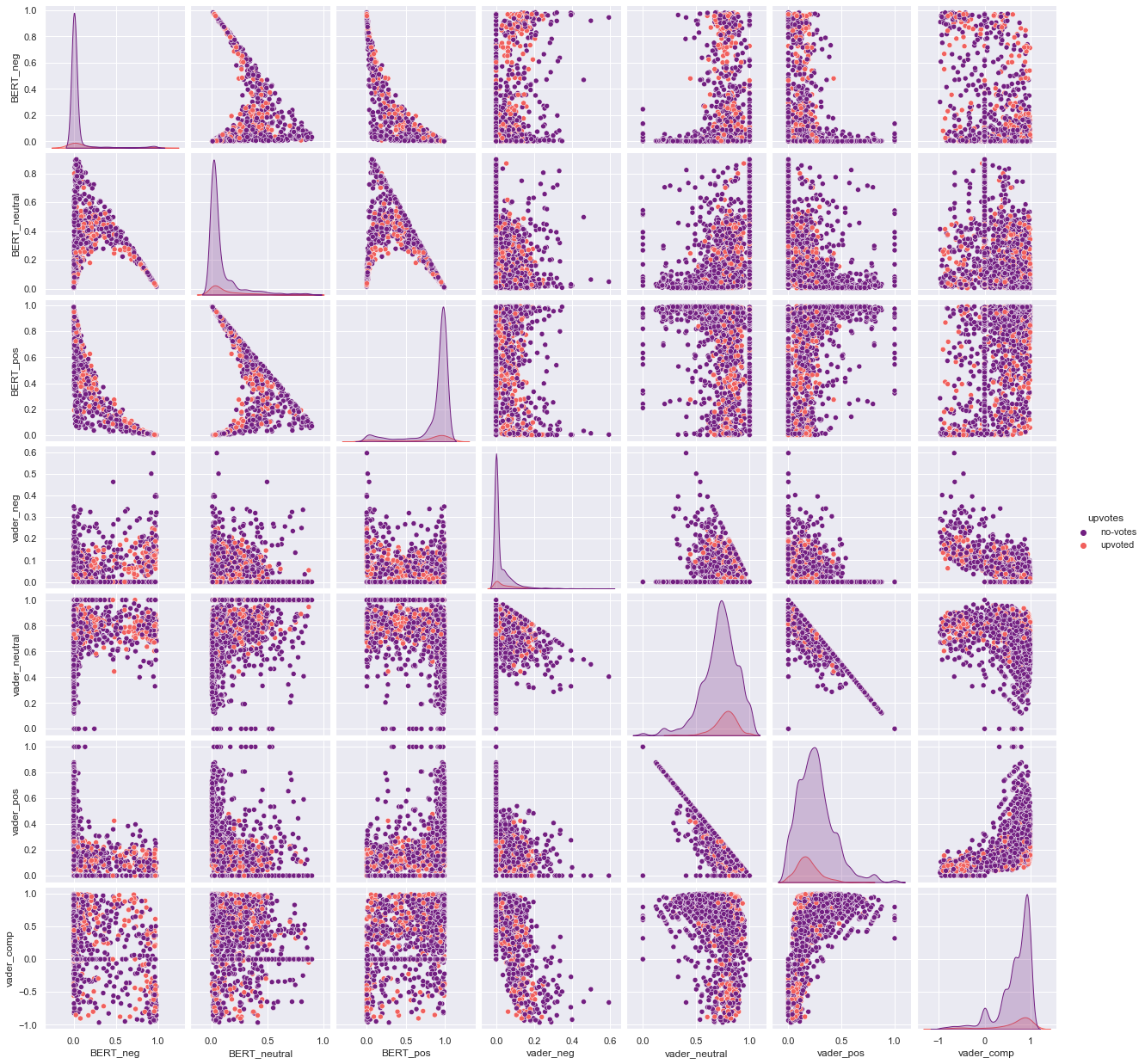
Sentiment Analysis for Skincare Product Reviews
Skills: NLP, VADER, BERT, DataViz, Pandas
By using two different algorithms, VADER (Valence Aware Dictionary and sEntiment Reasoner) and BERT (Bidirectional Encoder Representations from Transformers), this notebook was able to predict client sentiments over a product by its review. This application can be a useful for in e-commerce channels, where it has hundreds or thousands reviews, and automatically analyze customer feedbacks and better tailor responses accordingly.
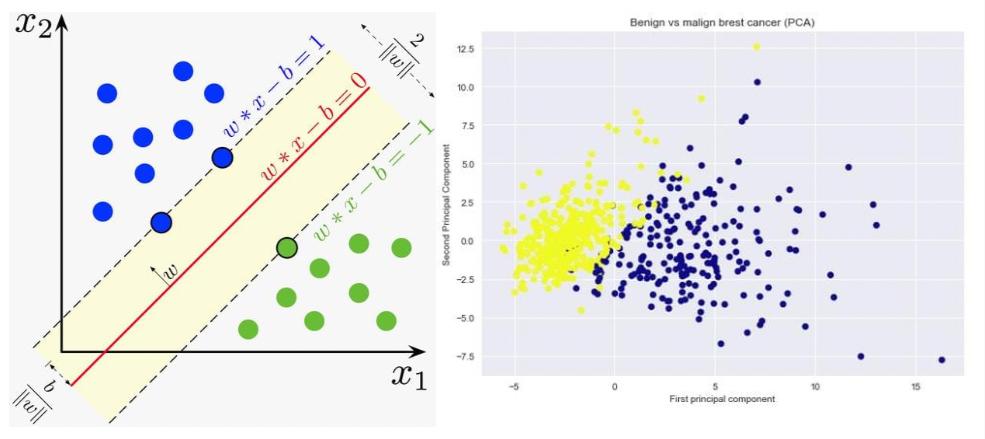
Brest Cancer Classification with PCA & SVM
Skills: SVM, PCA
This Machine Learning model was build with the objective to better predict if a Brest Cancer is either Benign or Malignant. To train and test the model, it was used the 'Breast Cancer Wisconsin Database', and built with PCA decomposition and the SVM classifier -predict Cancer class (1: Malignant | 0: Benign).
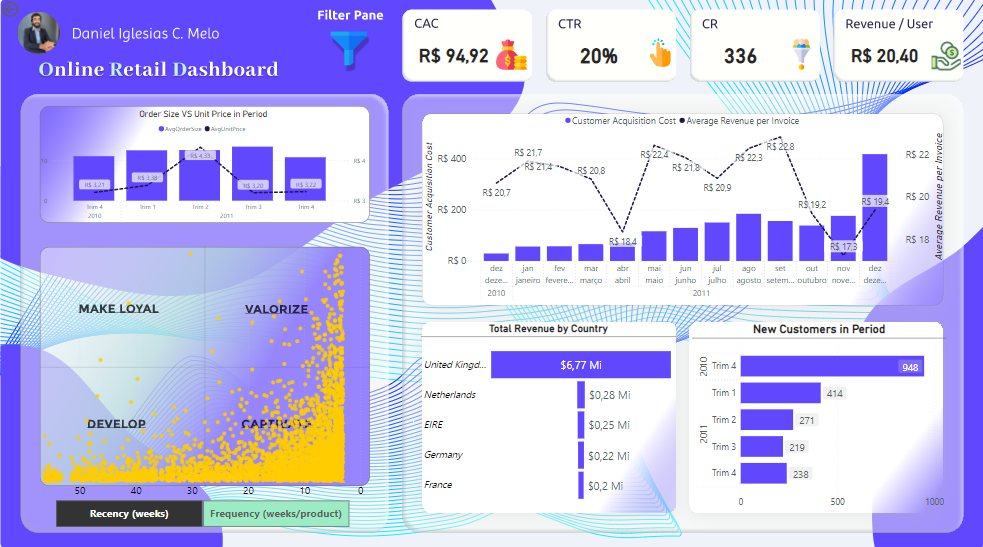
Business Intelligence Analysis
Skills: PowerBI, Dashboards, Data Visualization
I created this website as a practice, to post my solutions to challenging business cases. It has real and simulated cases, you can open the website to see more.
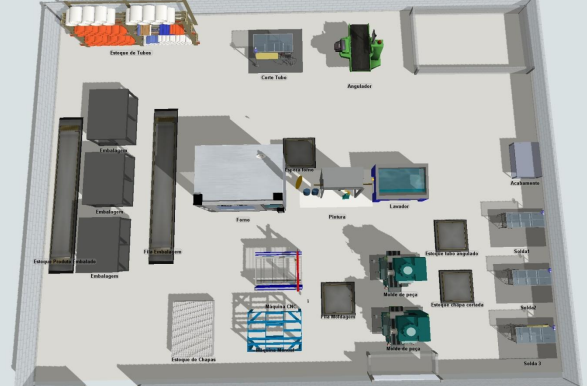
College Article: Optimization model using Discrete Event Simulation
Skills: Statistics, Operations Research
Research paper published during college graduation, together with some fellow students. Project helped decision making and enhanced company results, being an essential factor for their success. The computational simulation is founded as an auxiliary and complementary tool to the decision.
Page template from evanca